Skip to content
GitLab
Explore
Sign in
Primary navigation
Search or go to…
Project
C
cours
Manage
Activity
Members
Labels
Plan
Issues
Issue boards
Milestones
Wiki
Code
Merge requests
Repository
Branches
Commits
Tags
Repository graph
Compare revisions
Snippets
Build
Pipelines
Jobs
Pipeline schedules
Artifacts
Deploy
Releases
Package registry
Model registry
Operate
Environments
Terraform modules
Monitor
Incidents
Analyze
Value stream analytics
Contributor analytics
CI/CD analytics
Repository analytics
Model experiments
Help
Help
Support
GitLab documentation
Compare GitLab plans
GitLab community forum
Contribute to GitLab
Provide feedback
Keyboard shortcuts
?
Snippets
Groups
Projects
Show more breadcrumbs
algorithmique
cours
Commits
18818f34
Verified
Commit
18818f34
authored
3 years ago
by
orestis.malaspin
Browse files
Options
Downloads
Patches
Plain Diff
added exercises
parent
31e592be
No related branches found
No related tags found
No related merge requests found
Pipeline
#15160
passed
3 years ago
Stage: test
Changes
2
Pipelines
1
Show whitespace changes
Inline
Side-by-side
Showing
2 changed files
slides/cours_13.md
+93
-0
93 additions, 0 deletions
slides/cours_13.md
slides/figs/fig_hash.png
+0
-0
0 additions, 0 deletions
slides/figs/fig_hash.png
with
93 additions
and
0 deletions
slides/cours_13.md
+
93
−
0
View file @
18818f34
...
...
@@ -515,8 +515,101 @@ J_3 = 109 Delta = 2
d_3 = 7
/
J_4 = 116
--------------------------------------
J_{i+1} = J_i + d_i,
d_{i+1} = d_i + Delta, d_0 = 1, i > 0.
```
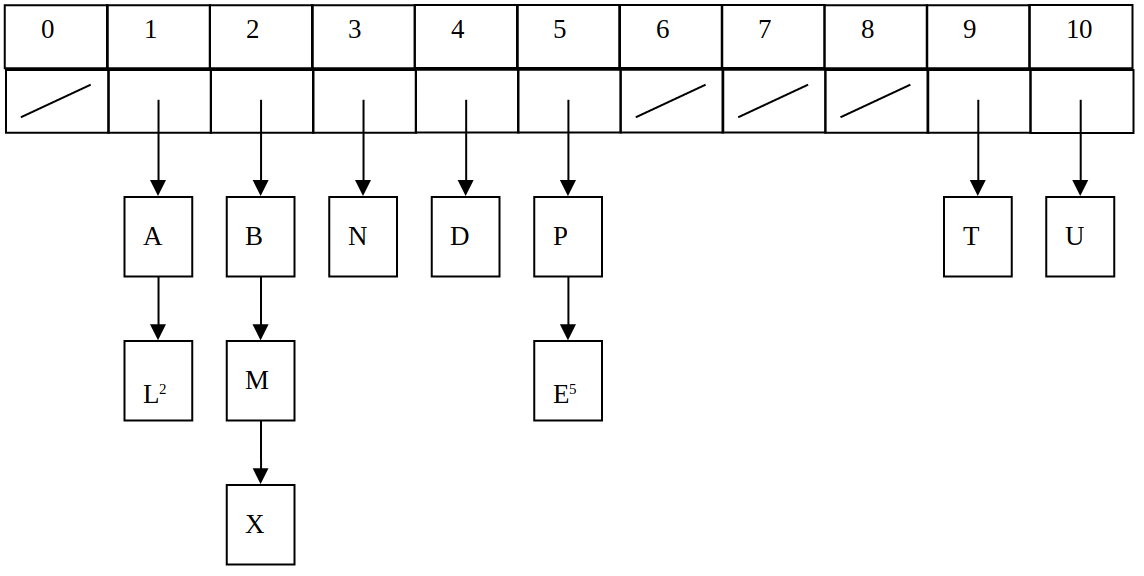
# Méthode de chaînage
## Comment ça marche?
*
Chaque index de la table contient un pointeur vers une liste chaînée
contenant les paires clés-valeurs.
## Un petit dessin
```
```
# Méthode de chaînage
## Exemple
On hash avec la fonction
`h(key) = key % 11`
(
`key`
est le numéro de la lettre
de l'alphabet)
```
U | N | E | X | E | M | P | L | E | D | E | T | A | B | L | E
10 | 3 | 5 | 2 | 5 | 2 | 5 | 1 | 5 | 4 | 5 | 9 | 1 | 2 | 1 | 5
```
## Comment on représente ça? (à vous)
. . .

{width=80%}
# Méthode de chaînage
Avantages:
*
Si les clés sont grandes l'économie de place est importante (les places vides
sont
`NULL`
).
*
La gestion des collisions est conceptuellement simple.
*
Pas de problème de regroupement (clustering).
# Exercice 1
*
Construire une table à partir de la liste de clés suivante:
```
R, E, C, O, U, P, A, N, T
```
*
On suppose que la table est initialement vide, de taille $n = 13$.
*
Utiliser la fonction $h1(k)= k
\m
od 13$ où k est la $k$-ème lettre de l'alphabet et un traitement séquentiel des collisions.
# Exercice 2
*
Reprendre l'exercice 1 et utiliser la technique de double hachage pour traiter
les collisions avec
\b
egin{align
*
}
h_1(k)&=k
\m
od 13,
\\
h_2(k)=1+(k
\m
od 11).
\e
nd{align
*
}
# Exercice 3
*
Stocker les numéros de téléphones internes d'une entreprise suivants dans un
tableau de 10 positions.
*
Les numéros sont compris entre 100 et 299.
*
Soit $N$ le numéro de téléphone, la fonction de hachage est
$$
h(N)=N
\m
od 10.
$$
*
La fonction de gestion des collisions est
$$
C_1(N,i)=(h(N)+3
\c
dot i)
\m
od 10.
$$
*
Placer 145, 167, 110, 175, 210, 215 (mettre son état à occupé).
*
Supprimer 175 (rechercher 175, et mettre son état à supprimé).
*
Rechercher 35.
*
Les cases ni supprimées, ni occupées sont vides.
*
Expliquer se qui se passe si on utilise?
$$
C_1(N,i)=(h(N)+5
\c
dot i)
\m
od 10.
$$
This diff is collapsed.
Click to expand it.
slides/figs/fig_hash.png
0 → 100644
+
0
−
0
View file @
18818f34
17.6 KiB
This diff is collapsed.
Click to expand it.
Preview
0%
Loading
Try again
or
attach a new file
.
Cancel
You are about to add
0
people
to the discussion. Proceed with caution.
Finish editing this message first!
Save comment
Cancel
Please
register
or
sign in
to comment
{kind=link}