Updated doc
Showing
- src/figs/dispatch_1d.png 0 additions, 0 deletionssrc/figs/dispatch_1d.png
- src/figs/distributed_systems.graffle 0 additions, 0 deletionssrc/figs/distributed_systems.graffle
- src/figs/distributed_systems.png 0 additions, 0 deletionssrc/figs/distributed_systems.png
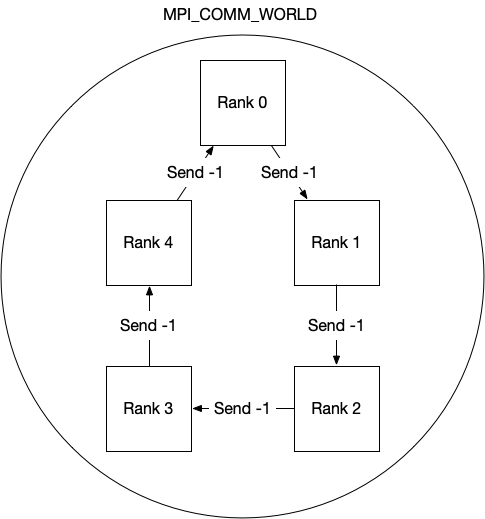
- src/figs/ring.png 0 additions, 0 deletionssrc/figs/ring.png
- src/text/00-preface.md 12 additions, 6 deletionssrc/text/00-preface.md
- src/text/03-programmation-parallele.md 9 additions, 5 deletionssrc/text/03-programmation-parallele.md
- src/text/09-lattice-boltzmann.md 1 addition, 1 deletionsrc/text/09-lattice-boltzmann.md
- src/text/10-conclusion.md 4 additions, 2 deletionssrc/text/10-conclusion.md
{kind=link}
{kind=link}
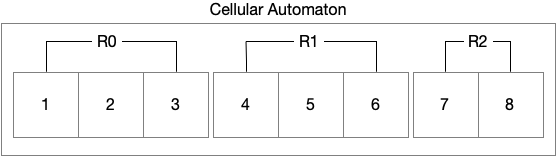
| W: | H:
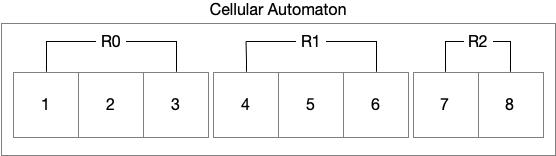
| W: | H:
src/figs/distributed_systems.graffle
0 → 100644
File added
src/figs/distributed_systems.png
0 → 100644
{kind=link}
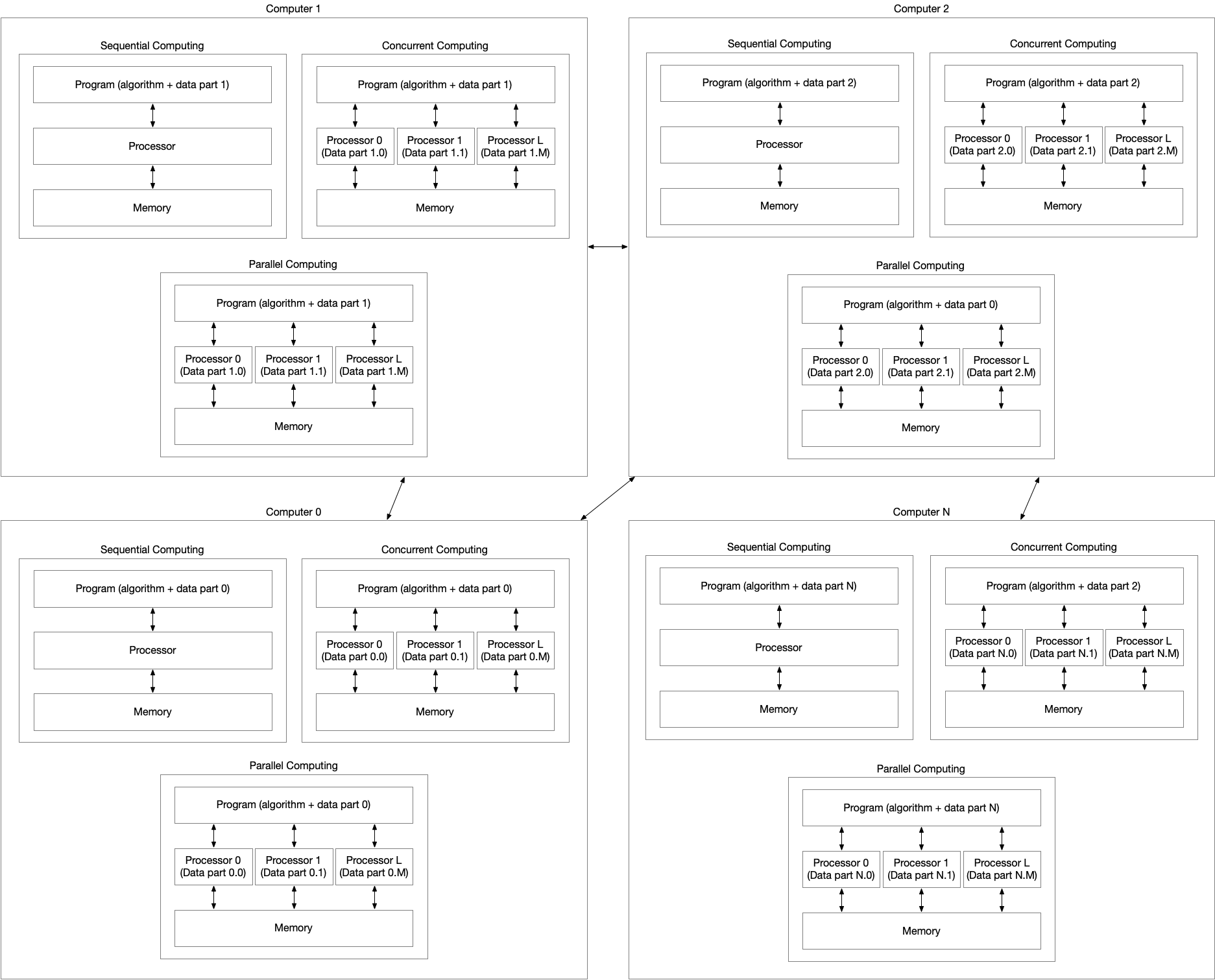
157 KiB
{kind=link}
{kind=link}
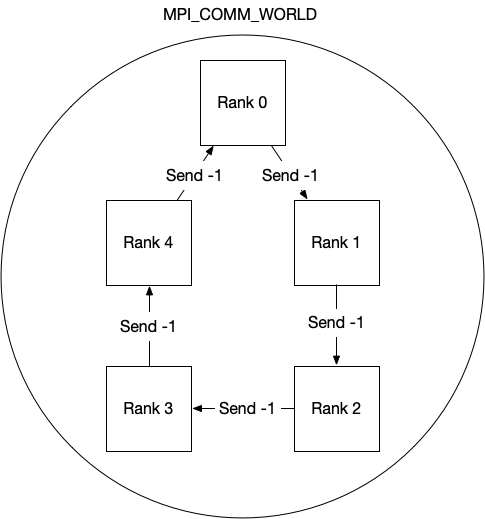
| W: | H:
| W: | H: